昨年末に以下のような投稿をした。
最近LLM + 探索がホット
— Kosuke Nakago (@corochann) November 29, 2023
チェス・将棋・囲碁は学習による評価値と膨大な探索でコンピュータが人間を越すようなものが作れた。
LLMというコンパスをつかって、ゲームではなく知的空間を探索できるようになった。今後どんな発見ができるのか、楽しみ。
OpenAIではQ* と言われるプロジェクトが水面下で動いているという噂があるとかないとか。読み物としては以下が面白かったです。
最近Google Deepmindが”FunSearch”、”AlphaGeometry” の論文を出したが、LLM+Searchはもっと汎用的にワークする可能性があり、今後もこの方向性でインパクトのある成果を量産してくるのではないかと思っています。
ではLLMを用いて探索を行うというのは具体的にはどういうことを指すのか、直近の論文動向を紹介します。
Contents
タスク(思考)を分解して、正しい答えに辿り着くタイプ
まず最初に紹介する3つの論文は探索というよりは、思考の分解です。ゴールに辿り着くまでの経路をきちんとステップに分けて、1つ1つ考えることで正しい答え(ゴール)に到達する精度が上がります。
CoT: Chain of Thought
“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”
https://arxiv.org/abs/2201.11903
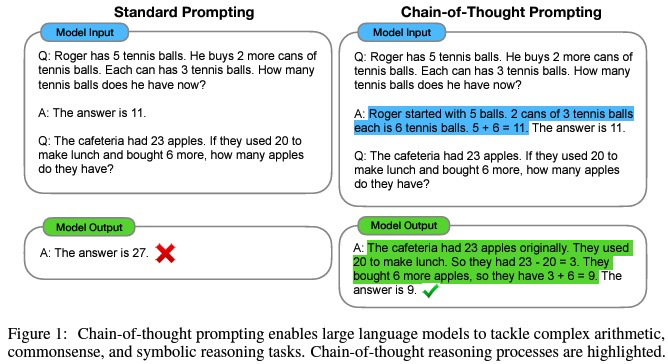
これは、Few shot exampleをPromptとして与える際に、回答に至る思考過程を含めて上げることで答えの精度が向上することを示した論文です。上図の具体例を見るとわかりやすいですね。このように、1発で答えを出すのではなく、途中経路を含めて思考を実際に出力することで正しい答えに行き着くことができるようになります。
この派生で、Zero-shot-CoTというものも提案されています。
“Large Language Models are Zero-Shot Reasoners”
https://arxiv.org/abs/2205.11916
こちらのPromptはもっと単純で、”Let’s think step by step” という言葉を入れるだけで回答精度が向上するというもの。使うのがとても簡単で引用も多くされている論文です。

オリジナルのCoTの用にFew shot exampleをいれなくても、”Let’s think step by step” の一文を入れるだけでLLMが問題に応じて思考/タスクを分解して考え、正しい答えに到達することができています。
ReAct: Reasoning and Action
“ReAct: Synergizing Reasoning and Acting in Language Models”
https://arxiv.org/abs/2210.03629
https://react-lm.github.io/
CoTではReasoningだけだったのに対し、ReActはActionとしてWeb検索(より具体的にはWikipediaから関連する文章を検索し、LLMへの入力として補完)を加えることで性能向上をしています。

AutoGPT
https://news.agpt.co/
https://github.com/Significant-Gravitas/AutoGPT
ReActをさらに発展させて、いろいろな作業を自動化してくれるようにしたツール。
例えばこちらの例では、コーディングを全くせずに3分でWebサイトの構築ができたデモが共有されています。
LLM + Search: LLMを再帰的に利用して探索
さて、ここからが今回の本題で、目標に対する最適化を、LLMを再帰的に利用して探索することで達成するタイプの研究です。
Voyager
“Voyager: An Open-Ended Embodied Agent with Large Language Models”
https://voyager.minedojo.org/
https://arxiv.org/abs/2305.16291
https://github.com/MineDojo/Voyager
LLMを用いたOpen World Searchの例として、Minecraftをとかせています。
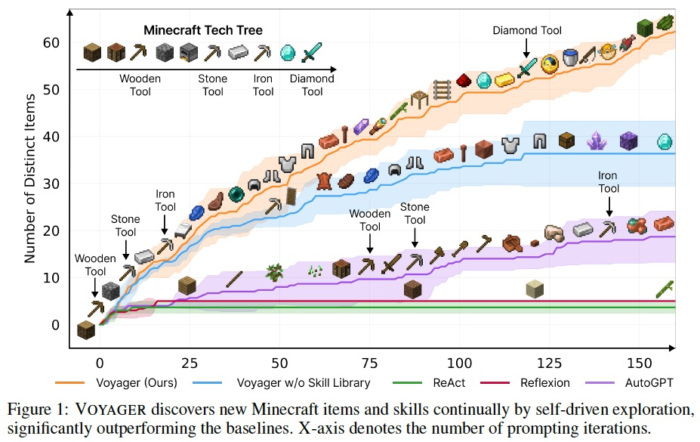
上述したReActやAutoGPTよりも以下のような独自の工夫を取り込むことで良い性能が出ており、Diamond Toolの発見までできています。
- 1. Automatic Curriculum
- 次に解くべき小タスクを決めます。現在の自分自身の入力をもとに、難しすぎず新しいタスクを考えます。(LLM自身にはある程度Minecraftの事前知識があることは良しとされているように思われます)
- 2. Skill library
- ソードと盾を装備してゾンビを倒す”combatZombie”など、ある程度の塊のコードを関数化=Skill化し、それをSkill Libraryに登録しておくことで、以降それらのSkillを参照し呼び出せるようにしています。こうすることにより、過去に成功した複雑な動作を使い回すことができます。
- Skill Libraryの参照にはRAGのように、そのSkillの説明文に対するEmbeddingを用いています。
- 3. Iterative prompting mechanism
- 現在の自身周辺の環境状態や、コード実行時のエラーなどをもとに、次の実行修正などを考えます。

この論文ではLLMのOpen world searchの能力を見ることを目的とし、画像入力や生のコントローラーコマンド出力ではなく、MinecraftのAPIを経由して現在状態の取得や行動をおこなっています。
- LLMが出力するいろいろなコードを実行させてみて、その挙動を見ることで、所望のアウトカムが得られるような行動=Skillを獲得していく
- Skill Libraryという概念を通じて、自分自身の成長を取り込みながらより難しいタスクに挑戦していくことができる。
といったあたりでLLMを用いた探索が活用されています。Minecraftの事前知識があったからここまでうまく解けたのかもしれませんが、考え方は汎用的でいろいろなタスクに応用できる可能性を感じました。
以下3つはDeepMindの論文です。どれもタスクの達成度合いを定量的にスコアリングできるようなタスクに対して、そのスコアを上げるような出力をLLMを用いて探索しています。
RestEM
“Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models”
https://arxiv.org/abs/2312.06585
ReST: Reinforced Self-Training
EM: Expectation Maximization
を組み合わせた手法、ReST^EMを提案しています。
1. Generate (E-step): The language model generates multiple output samples for each input context. Then, we filter these samples using a binary reward to collect the training dataset.
2. Improve (M-step): The original language model is supervised fine-tuned on the training dataset from the previous Generate step. The fine-tuned model is then used in the next Generate step.
LLM自分自身に回答候補を複数出力させるE-stepと、その中で良かった候補をデータとしてSFTすることでLLMを改善させていくM-stepとで構成されています。

本論文では、以下2つの定量評価が可能なタスクに対して提案手法がうまくいくことを示しています。
- MATH (Mathematical problem solving): Hendrycks’ MATH dataset
- APPS (Code Generation): APPS (Introductory) dataset.
E-stepは更新されたLLMを用いつつも、M-stepは毎回Pretrained weightからFine tuneしているようで、とにかくOverfittingが問題になっていそうでした。
FunSearch
“Mathematical discoveries from program search with large language models”
https://www.nature.com/articles/s41586-023-06924-6
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
Deepmindから、Natureの論文です。
FunSearchは、Function space searchの略で、LLMを用いて難しい問題に対してより良いスコアが得られるような関数(解法・アルゴリズム)を探索します。探索の際、Evolutionary Algorithmを用いてよいコード生き残らせながらどんどん進化させていくことでよりよいアルゴリズムが得られる仕組みとなっています。
論文では、cap set problem, online bin packingの2つの問題において、既存のヒューリスティックアルゴリズムよりもよいアルゴリズムを見つけることに成功しています。
全体の仕組みとしては、学習済みLLM (Code出力に特化したCodeyを使用) から解の候補を出力させ、それぞれのスコアを評価した後、生き残らせるものをPrograms dabaseに保存していきます。
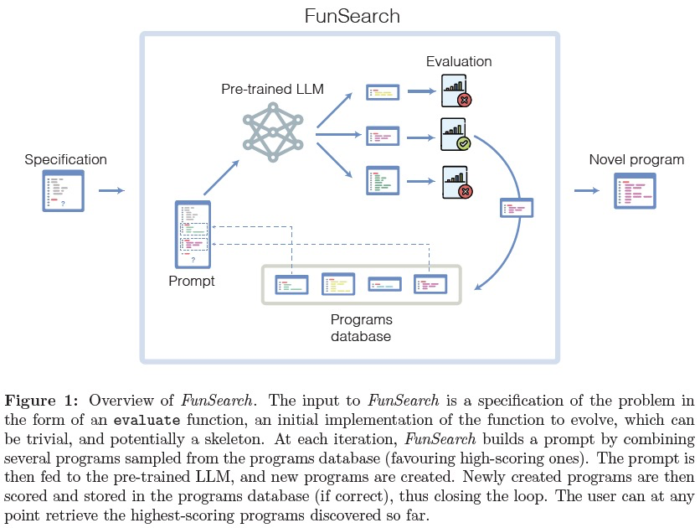
次の解の候補を出力する際はEvolutionary Algorithmをもちいて、より良い候補にしていきます。このEAの部分はかなりヒューリスティックな印象があったので今後もっと改善されていくかもしれません。
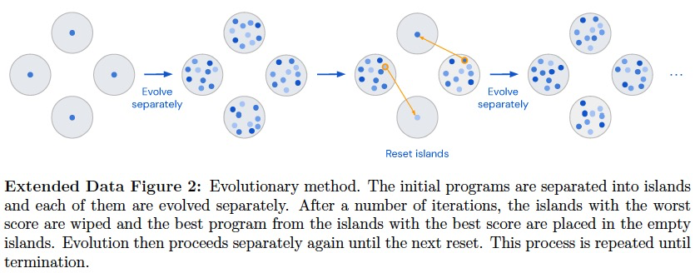
また、プログラム出力をさせる際の工夫として、完全にゼロからコードを考えさせるのではなく、その問題に特化したテンプレートは与えてあげて、ヒューリスティクスアルゴリズムのコアになる部分 (下図の priority, heuristic) だけを考えさせるようにしているようです。

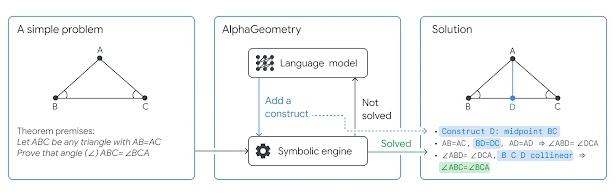
AlphaGeometry
“Solving olympiad geometry without human demonstrations”
https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/
https://github.com/google-deepmind/alphageometry
こちらもDeepmindからNature論文です。
国際数学オリンピック(IMO)の幾何問題を30問中25問解くことができたようです。
Neuro Symbolic approachを用いており、幾何問題を機械が扱うシンボルに変換しながら解いていくようです。ここで使われているLanguage modelは、専用のデータセットを1億件用意して学習したと書かれており、汎用的なLLMから出発したわけではなく、最初から本タスク専用に作成したモデルを用いていそうです。
まとめ
LLMを用いることで、複雑な問題に対する検討の際に自動で小タスクに分ける(経路を分解する)ことができるようになり [CoT]、必要に応じて外部から情報を取ってくる・行動を起こしてその変化を見るといったこともできます [ReAct, AutoGPT, Voyager]。探索の過程で得られた知見を保持しておき、将来”Skill” などとして有効活用することもできたり [Voyager]、Brush upさせながら改善していくこともできます [FunSearch]。探索過程の結果を学習データとして、LLM自分自身をそのタスクに特化したスペシャリストにしていくこともできます [Rest^EM]。
一方で、REST^EM、FunSearch、AlphaGeometryは全て、解の出力後にその解の良さ具合(reward)をすぐに評価できることを前提としています。そのためか、現時点では数学・コーディングの問題に適用範囲がとどまっているようです。
LLMを用いることで、入力・出力が定型でないようなタスクが扱いやすくなったため、探索対象として考えられるアプリケーションはまだまだたくさんあると思います。今後もこの領域で面白い成果が出てきそうで楽しみです。
興味深い記事をありがとうございます
個人的に大量のLLM系の論文を表形式にまとめています
もし興味があれば見てみてください
https://potent-twister-29f.notion.site/b0fc32542854456cbde923e0adb48845?v=e2d14d2ef0c848f5a1d5b71f9977d7c5&pvs=74
https://github.com/shure-dev/Awesome-LLM-Papers-Toward-AGI