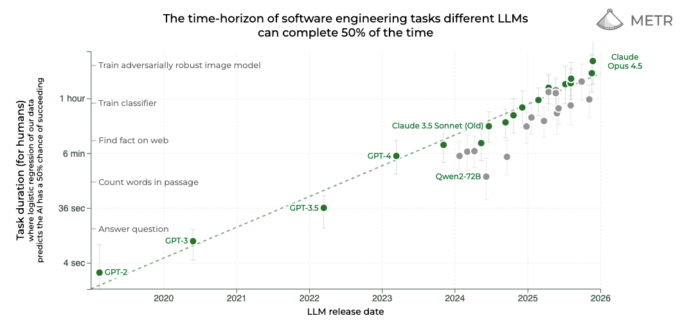
年末の時期ということで今年の復習を兼ねて、2024年末頃から2025年にかけて発売されたAI関連の技術書を紹介します。
ただ本の内容のまとめを書くだけだとAmazonのレビューなど見ればわかると思うのでそれは短めにしつつ、対象読者(難易度)や、知っている範囲で著者についての背景情報について触れたり、本のスコープ外の関連分野も少し触れたりして書いてみようと思います。
順序としてはアプリケーションよりの内容(AI Agent)からはじめ、開発、モデル、基礎理論よりに移っていきます。(なのでおすすめ順ではないです。)
現場で活用するためのAIエージェント実践入門
2025年はAI Agentの年とも言われていました。そのAI Agentを体系的に学ぶ際におすすめの本です。
Xに投稿した通り なのですが、この本の凄さはその視野の広さ!まさにResearch、Engineering、Business実用まで幅広く、しかもきちんとカバーされてされています。
Research動向を追うという観点では論文だけでも100本以上?カバーされていて最先端のキャッチアップにも最適でしたし、その実応用は第2部で2025年現在の現場で導入されるレベルのAI Agentの周辺環境構築がどのように行われているかもコードレベルで勉強できます。著者が実際に第一線で働かれているので実践的なコードを学習することができます。
エンジニアだけではなく、生成AI活用を考えるビジネス開発をしている方も第1部と第3部は読みやすく、今後の案件の取り方とかに活かせるのではないかなと思いました。特に第10章では著者陣が所属するそれぞれの会社(電通総研・Algomatic・Generative Agents)における三者三様な案件の取り方・進め方の違いが具体的に書いてあり、実務を通して行き着いた戦略などを知ることができ参考になります。
著者の一人である太田真人さん(@ottamm_190 )は現職Sakana AIにて一緒に働いているのですが、2024年末までWeekly AI Agents Newsをやっていたり↓、2024年末にAI Agentの今後についてまとめた記事を出していたりしました。これらも論文レベルの理解から、それをビジネスにつなげるとはどういうことか、体系的にまとめて幅広く書いていました。
AI Agentに関する論文をカテゴリごとに分類したgithub repoのmasamasa59/ai-agent-papers の方は現在も更新されているようです!
LangChainとLangGraphによるRAG・AIエージェント[実践]入門
Workflow型のAI Agent を構築する場合の実際のコーディングについて学びたい際に最適な本です。特にLangChain, LangGraphといった人気の高いライブラリを使いながらAI Agent構築をしていく方法がわかります。
LangSmithという機能を組み込んだ状態でLangchainを使うとすごい見やすく管理できる(Tracingといいます)というのがしれるのは良いし、 RAGのコード例もBM25+Vector SearchのHybrid RAGまでしっかりやっていてクオリティが高く、簡単なAgentを組む例もしっかり乗っていました。LangGraphをどのように使うのかの説明は後半にあります。
Generative Agents社 の創業者3名で書かれている本なのですが、この会社は教育・研修サービス なども手掛けていて、教えるのコンテンツつくるのが本当に得意なんだなというのが伝わってきます。この本は「ChatGPT/LangChainによるチャットシステム構築[実践]入門 」の後継に当たるような本になっています。CEO西見さんは前述の「現場で活用するためのAIエージェント実践入門」の著者でもありますね。
似たようなAI Agent開発寄りの本としてはML Bearさん の「つくりながら学ぶ!生成AIアプリ&エージェント開発入門 」もおすすめです!こちらは、この本のもとになったZennで公開されている「つくりながら学ぶ!AIアプリ開発入門 – LangChain & Streamlit による ChatGPT API 徹底活用 」の方は無料でもコンテンツを見ることができます。こちらはStreamlitライブラリを使用したUI込みのアプリケーション構築まで細かく説明があり、1エンジニアがpythonだけで短いプログラム書くだけで生成AIを取り入れたアプリケーション構築ができる時代になっているということがわかります。ML_Bearさんといえばちょうどこんな2025年ふり返り記事 を出されていました👀 (はい、、実は今同じ会社で働いていますっ)
Polarsとpandasで学ぶ データ処理アイデアレシピ55
これまでpythonの表形式データの分析ではpandas が使われていました。polars は内部をrust実装で作成することでより高速な表形式データの処理ができるライブラリで最近人気になってきています(pandaに対してpolarで、もちろんpandasを意識して命名されています)。Kaggleを見ていても、どんどんpolarsを使用している例を見るようになってきており今後大きなデータを扱う際には知っておくと良いと思い読んでみました。
公式のUser guide も充実していますが、本という媒体でもっておくと電車の中で読めたりするので、まとまった文章一気に読めて理解がはかどって良かったです。
Polarsのコンセプトとして、Expressionを用いて処理を記述し、できるだけ処理をまとめたあとに最後一気に並列で実行できるようにしている(embarassingly parallel )ことや、lazy frameを用いることで処理のGraphを作成・最適化してさらなる複雑な処理フローの高速化までできるということなどがわかりました。Rust実装されているだけではなく、たしかにそういう並列化、処理のコンパイル最適化の工夫があるなら速度がこれまでの10倍とかで実行できるのも頷ける。大きいデータ扱うときは積極的にPolarsを使ってみたいと思った。メモリ消費もBackendでApache arrowを使うことで効率化されているっぽい。
著者の1人である@sinchir0 さんは今年の関西Kaggler会#3 にてLLMの量子化xファインチューニング のAblation studyについて発表されていたり、来年発売予定の「Kaggle ではじめる大規模言語モデル入門 」の著者でもあり楽しみしています。
実践Claude Code入門―現場で活用するためのAIコーディングの思考法
*12/26発売でまだ読めてないので後日アップデートします。
ここからはいくつかAI駆動開発に関する本を紹介します。2025年はエンジニアのソフトウェアの開発方法が一気に変わった年だったと思います。私自身も特にClaude Codeの出現前後辺りから一気に直接コードを書く量が減り、かわりにCoding Agentに対して自然言語で実装方針を伝えたり、質問したりするようになりました。それでもまだコーディングの実装やエラーの修正程度にしか活用できておらず、フル活用できている感覚がなく体系的に勉強しないとと思いいくつか読んでみています。
先程のGenerative agents社の3名による最新本です。
スペック駆動開発は、先日読んだMixSeek の開発手法としても採用されていたりしましたが(リポジトリのspecs ディレクトリ見るとわかります)、完全に日本語でアプリケーション開発が進むようになってきたことに驚きました。また、Claude codeにただコーディングをさせるだけでなくより自律的な使い方に興味があり、これらについて書かれていそうな本書を買ってみました。
Claude CodeによるAI駆動開発入門
この本のTutorialは「5分でフロントエンドのみのアプリケーション実装・デプロイ」→「30分でNext.jsを使ったより実践的なアプリケーションデプロイ」→「半日で社内システムデプロイ」と進んでいきます。あくまでもデモではあるものの、1アプリケーションが1日以内にデプロイまで含めて(しかもプログラミングなしに)完成してしまうのは改めて一気に時代が変わったという感じですね。
著者が実際に使っていて有用なMCP serverとの連携方法(context7, serena, playwrightなど)、CLAUDE.mdに要件を定義させていきながらステップを分けて開発していく方法、gh commandと連携させてgithub issueやPRの作成まで自動化させる、Claude codeをgithubにインストールしておきgithubアプリをスマホに入れておくことでリモートから簡単な開発をできるようにしておくなど、、現在のテクニック集が詰まっていて参考になりました。
本書の題材はtypescriptをメインにアプリケーション開発するものが基本で、pythonや機械学習といった要素は無いです。
著者の平川さん(@t_hirakawa )は、株式会社en-gine の代表をされているようです。
これらの本を読む前には以下のような本を読んでいました。今後も仕様駆動開発などが出てきていたりと、まだまだ開発方法は大きく変化する過渡期の中にいるのだと思っていて3~6ヶ月ごとに最新の本読んで学び直すくらいのキャッチアップは必要になるのだろうなと思っています。
「コード×AIーソフトウェア開発者のための生成AI実践入門 」
github copilot など、生成AIを用いたコード開発支援を使うようになってきたことによる、開発手法の変化などについての説明本。具体的にgithub copilotなどを使いこなすための本という感じではなく(機能の具体的な説明やテクニックなどの紹介は少ない。)、もっとマクロに生成AIからコード支援を受けられるようにするにはどういうコードを書いていけば良いか、という話が書いてある。
それは結局AIにもわかりやすいように変数名をGlobalでConflictしないようにつけよう、意味のある関数単位でRefactorしようなど、クリーンコードを書こう、という感じでこれまでのベストプラクティスがAI活用にも役立つという話でした。
ただ、人間がレビューをする必要がある、ボトルネックになるのは人間のレビュー速度であり、それは1時間で500行程度 、というような見解を示しているのは学びで面白かった。
Promptをどのように書くと良いか、さまざまなアプリケーションがどのようにPromptを作り込んでいるか?とかの紹介もありそこは勉強になった。AppendixのPractice Guideにまとめ があるので、ここを読み返すとどんなこと書いてあったかの復習ができる。
著者の服部さんはgithubで働いており、社内でコード資産を活用し合えるようにする、インナーソース の支援に取り組まれているようでそういう話も書いてあったりします。
「AIエディタCursor完全ガイド: やりたいことを伝えるだけでできる新世代プログラミング 」も読み当時はおすすめだったのですが、すでにCursorのUIや機能アップデートが多く、AI Codingの分野は当面は有効期限半年程度だと思って新しい書籍を探したほうが良い気がしています。
AI Coding支援に関しては今年できることが格段に変わってきているので、その位の頻度で学び直すくらいの価値はある分野だと思います。また、Coding分野での(エンジニアの業務活用に対する)生成AI活用は他の業界と比べても格段に進化が早く、他業界での生成AI社会実装を考える際のヒントとなることも多いと思うため、どういう試行錯誤があって今の動向があるかまで把握しておくことは価値があると思います。
Data-centric AI入門
Xでも投稿したので埋め込んでおきます。
私個人的には最近読んだ本の中で一番好きでした。AIの研究界隈ではモデルArchitectureに意識が活きがちであるが、実応用に当たってはデータ側を見るのが重要で、そこに対してどういうアプローチが存在しているかまとまっています。単純に画像・言語・ロボットというメジャー領域をカバーしたDeep Learning時代のAI研究動向復習本としても最高だと思います。
以下にYouTube liveでの本の解説もあります。
VIDEO
また、Data-Centric AI Community というconpassのコミュニティ活動も行っているようで、今度参加してみたいなと思っています。
著者の方は私個人は面識ないのですが、それぞれの領域の最先端を研究されている方がきちんと研究動向をおさえて各章を書いてくださっています。監修の片岡さんは後術する「Vision Transformer入門」も監修されているのですが、こちらもすごくおすすめです。
本とは関係ないのですが、TuringがData Centric AIを推し進めて 完全自動運転の実現を目指していますね。
基盤モデルとロボットの融合 マルチモーダルAIでロボットはどう変わるのか
第4次AIブームの次に更にでかい波が来るとしたら、ロボット基盤モデル・Physical AIではないかということで、この分野には大変注目しています。日本ではまだまだRobotics領域の基盤モデル開発に取り組む企業は少ないですが、海外ではかなり本格化してきていますね。
本書では第5章までにこれまでのアプローチの復習として、低レベル認識→高レベル認識→高レベル計画→低レベル計画(制御)の4つのモジュールに分けてモデルを用いるアプローチのそれぞれのモジュールへの基盤モデルを活用するアプローチが紹介されており、第6章で今後のメインストリームになっていくであろう全モジュールをEnd to endでつなげたロボット基盤モデルに対する説明がなされています。第5章までの先行研究の紹介が豊富で、今のロボット基盤モデル開発にいたるまでの先行研究を復習するのにとても良かったです。
第6章部分のロボット基盤モデルに関しては、この本の発売後にもすでにFigure AIからhelixがでてきたり、Physical Intelligenceからもπ0.5 , π*0.6 がでてきたりと、本当に進展が早く2026年に本が出るならもう第6章部分だけで1冊になるような研究の進展になっていくのだと想像しています。
https://www.figure.ai/helix より。Figure AIのhelixは高速な制御のためのSystem 1と、賢い計画のためのSystem 2が異なる周波数で動きながら1つのシステムとして動作する。著者の河原塚さん (@KKawaharazuka )は、前述のData-Centric AI本でもロボットデータの章を担当されていますし、Xでもすごい情報発信してくださっています。
ロボット基盤モデルに関してはSurvey論文 (Project page: https://vla-survey.github.io/ )や、スライド↓も公開されていたりします。
モジュールごとの開発からすべてのEnd to endでのアプローチに今後はメインストリームが移っていきそうという意味では再掲になりますが、Turingが自動運転領域でEnd to endの方にかけて技術開発を進めていますね。
VIDEO
Vision Transformer入門
2022年の本なのですが今読んでもとても良い内容でしたので共有します。Transformerはわかるが、Vision Transformerの方は??な状態だったので読んでみました。本自体はかなり専門的で、どちらかというと画像領域でAI技術開発をされる専門家向けの本です。
2章ではViTのArchitecture構造をそれぞれのモジュールごと(Position embedding, patch embedding, Multi-head self attentionなど、、)に図で説明しながら、実装レベルまで交えて書いてくれており理解がきちんとできました。そのうえで、では実際の挙動としてこれがどう働くの?というところで、Position Embeddingとしてなにが学習されているかの可視化や、CNN Archとの違いとして物体のテキスチャよりも形状に着目するような認識能力が獲得される→人間もテキスチャよりも形状でものを判断する傾向があるので人間に近いと言える、などなどViTの挙動を深く理解するための分析研究まで紹介されています。
さらに、SwinTransformerをはじめとした様々な後続研究がカバーされており、現在のCV領域に対するAI研究動向を把握するのにとてもよい本でした。
Data-Centric AIと同じく片岡さん (@HirokatuKataoka )が監修されており、著者の皆様もこの分野の最先端を研究されている方々が書かれており、どちらも本当に質が高いです。
原論文から解き明かす生成AI
原論文をちゃんと読み込む、というユニークなアプローチで書かれている本で、特に面白いのが第1章に”論文の読み方”に関する説明まであること。これはAIが論文の要約や、レポート作成などやってくれるようになってしまった今の時代において、特にこれから論文を読み始めることになる修士・博士の学生の方や、研究職就きたての方には是非読んでいただけると、ときには1次ソースをこれだけ深く読み込む事が必要なのか・書いてあることから広げていってどういう学びが得られるのかなどがわかって今後のためになるのではないかと思いました。
カバーされている論文も生成AIということでLLMに関してはもちろんですが、Transformerだけではなく、TokenizerとしてByte Paier Encoding (BPE)からSentencePieceまで説明があります。さらに画像の生成AIモデルとして拡散モデルからのDiffusion TransformerやCLIPなどの説明までありかなり幅広くカバーされています。
著者の菊田さん (@yohei_kikuta ) は、もともとユビーでVPoEなども担当されていた方で、現在はAWS Japanで働かれているようです。2025年の振り返り記事 も書かれていました。(←ちゃんと感想書いてみました!)
生成AIのしくみ 〈流れ〉が画像・音声・動画をつくる
<流れ>に着目して書いているとのことですが、中身は拡散モデルやフローマッチング、エネルギーベースモデルなどに関する説明がされています。数式を省いて、授業のように図をたくさん書きながら概念を説明してくれているのでわかりやすく理解が進むと思います。拡散モデルはテキストを生成するLLMではなく、画像や音声、動画の生成に使われている技術なので、そちらの領域の理解を深めたい方に良いと思います。
「拡散モデル データ生成技術の数理 」の数式を省いてわかりやすくした後続版という位置づけではあるものの、フローマッチングや。
岡野原さん はPFNの代表取締役社長で、私も前職では大変お世話になっていました。外部にも様々なメディアで発信されていて、Xでは@hillbig のアカウントで毎日最先端の論文の解説投稿をされていますし、日経ロボティクスでAI最前線 を毎月投稿していたり(有料です)、特にもともとPFN社内むけにおこなわれていたランチトーク を公開して配信しているものは最先端のAI研究トレンドがわかりやすく解説されているのでエンジニア層から非エンジニア層までメルマガ登録おすすめです!!
対称性と機械学習
上記と同じ岡野原さんの本ですが、こちらは開発の本というよりは数学理論の本でかなり専門性の高いものになります。
機械学習におけるNeural Networkの設計において、入出力の対称性(並進対称性とか、回転同変性とか)を保つ際に背後で働いている数学理論として群論 の説明(リー郡・アフィン郡・クリフォード代数など、、、)からされています。
私個人もMatlantis のプロジェクトに関わっていた際に使われていたNeural Network Potentialでは、原子位置の3次元座標の入力に対して、エネルギーや力の予測を出力する際に、3次元座標空間に対する回転対称性を求めるSO(3)、更に反転操作に対する対称性も課す O(3)、更に並進対称性を保つ E(3) 対称性などが望ましい帰納バイアス(というよりも物理法則)として存在していて、これを保つようにNeural Networkの設計がされていました。(SO(3)対称性を保つNeural Networkの設計を提案した初期の論文であるClebsh Gordan Net は量子力学を学んでないと理解難しいと思いますが、SO(3) 対称性を保つClebsh gordan積を非線形関数としてNeural Networkに組み込むものでとても面白いです。)
2026年始に読みたい本
「Kaggleではじめる大規模言語モデル入門 自然言語処理〈実践〉プログラミング (KS情報科学専門書) 」
Kagglerの takaito さん、u++ さん、sinchir0 さんが書かれた、KaggleのLLMコンペを題材にして自然言語処理に関する実践的な知識やプログラミングを学べる内容になっているとのことです。
書籍発売前から執筆の背景などがたかいとさん 、u++さん から書かれていたり、それぞれのコンペでの上位参加者から解説をお願いして作成されているなど、Kaggler界隈ではオールスター的な方々が関わって執筆された本のようで楽しみです。
たかいとさんは2025振り返り を見てもわかりますが、Kaggleなど様々なコンペに参加しながら、金融領域での研究もされていて論文も書き、この書籍も執筆されていたりとほんとにどれだけ活動されているんだというすごい方です。直近の関西Kaggler会でも発表されていました。
u++さん はたくさん発信をされているのでご存じの方は多いでしょう。この他にも様々なKaggle本の執筆に携わっていたり、継続して毎週Weekly Kaggle News の発信もされていたりします。